D2GRs2 源码阅读2-开源数据预处理
├── data
│ ├── preprocessor.py # 预处理两种数据集(下载、处理等)
├── preprocess_public_data.py# 数据预处理入口脚本
原始数据(movie-1m)包括三份文件
- 用户信息(用户 ID::性别::年龄::职业::邮政编码)
- 电影信息(电影 ID::片名::类型)
- 评分信息(UserID::MovieID::Rating::Timestamp)
处理数据:SASRec数据格式&Join用户特征
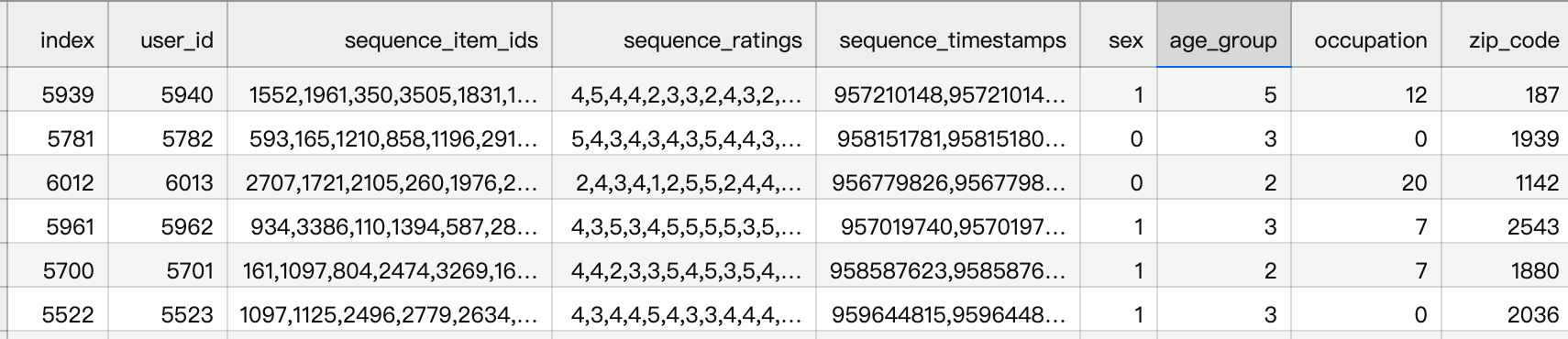
用户行为序列保留20以上:
| item_ids_mean | item_ids_min | item_ids_max | ||
|---|---|---|---|---|
| ml-1m | 165.597517 | 20 | 2314 | |
| ml-20m | 144.41353 | 20 | 9254 | |
| amzn_books | 14.467016 | 5 | 27508 |
按照不同用户划分训练集和测试集,例如:
ml-1m: train num user: 5436
ml-1m: test num user: 604
原文
4.1.1 开源数据的实验设置
We follow sequential recommendation settings in literature, including full shuffle and multi-epoch training
It is important to note that the evaluation methodology used here differs significantly from industrial-scale settings, as full-shuffle and multi-epoch training are generally not practical in streaming settings used in industry (Liu et al., 2022)
- Software-hardware co-design for fast and scalable training of deep learning recommendation models.
- facebook 大规模12 万亿个参数的非常大的 DLRM工作
baseline SASRec “Self-attentive sequential recommendation”
评估指标 HitRate@K、NDCG@K 偏召回
-
- 对比 均匀抽样、流行度抽样、全空间评估
-
《Revisiting neural retrieval on accelerators》
- 引用作者自己之前召回方向的工作
实验对比
hstu: 等同于前置1中SASRec的参数设置
hstu-large: 4x number of layers and 2x number of heads
结果表明,
a)HSTU在使用相同配置时显著优于基线
b)HSTU在扩大规模(scaled up)时进一步提高了性能
4.1.2 工业规模流式训练的实验设置
重中之重
- HSTU的实验效果
- HSTU的消融实验
- 各种Transformers的实验
排序的评估指标Normalized Entropy (NE) (He et al., 2014)
- GRs前置2 Practical lessons from predicting clicks on ads at facebook
- 优势: 可以评估“校准效果”。即auc不变,如果模型过分高估或者低估了,NE也会变化。
- 在本文实际场景中, NE降低千分之一就是显著的迭代了,可以带来线上5%的增长(10亿级用户)。
样本
- 我们训练了超过100B的样本(相当于DLRM)
- 每次作业使用64-256个H100
多任务
- engagement(E-task)本文应该类似点击
- consumption(C-task)本文应该类似浏览时长
召回的评估指标 log perplexity
- 类似于语言模型的评估
效果
- HSTU明显优于Transformers,尤其是在排序,这可能是由于逐点注意力(pointwise attention)和相对注意力偏差的改善(relative attention bias)
- 消融实验:消融的HSTU和HSTU之间的差距证实了我们设计的有效性。(为了提高训练的稳定性,基于Softmax的HSTU和Transformer的最佳学习率LR比HSTU低约10倍)(即使有更低的LR和预范数残差连接(Xiong et al.,2020),我们也经常遇到标准Transformers的损失爆炸loss explosions)。
- HSTU的性能优于LLM中使用的流行Transformer变体Transformer++(Touvron et al., 2023a),后者使用RoPE、SwiGLU等。总体而言,在这种小规模设置中,HSTU显示出更好的质量,训练完成时间(wall-clock time)快1.5x-2倍,带宽(HBM)使用量减少50%。
We fix encoder parameters in a smaller-scale setting (l = 3, n = 2048, d = 512 for ranking and l = 6, n = 512, d = 256 for retrieval), and grid-search other hyperparameters due to resource limits
在资源有限的情况下,本文选择了固定encoder的一些关键参数(l = 3, n = 2048, d = 512 for ranking and l = 6, n = 512, d = 256 for retrieval),并使用网格搜索方法来调整其他超参数,以期在小规模设置中找到最优的模型配置?
4.3 和传统推荐系统DRM的对比
召回
- 新增召回 E-Task +6.2% C-Task +5.0%
- 替代召回 E-Task +5.1% C-Task +1.9%
排序 - E-Task +12.4% C-Task +4.4%
性能
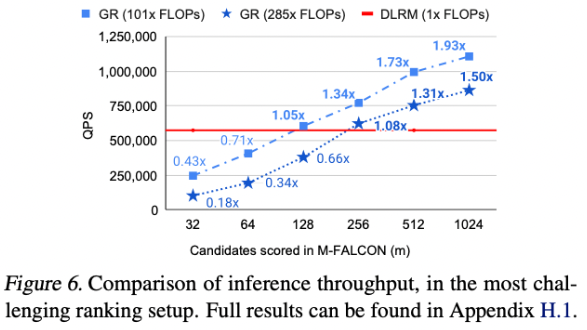
缩放率!!
结果如图7所示。
在低计算条件下,由于手工制作的特征,DLRM可能优于GRs,这证实了特征工程在传统DLRM中的重要性。
然而,GRs相对于FLOP表现出了更好的可扩展性,而DLRM的性能则停滞不前,这与先前工作中的发现一致。我们还观察到嵌入参数和非嵌入参数都具有更好的可伸缩性,GRs导致1.5万亿个参数模型,而DLRMs的性能在约2000亿个参数时饱和。
-
召回
-
排序
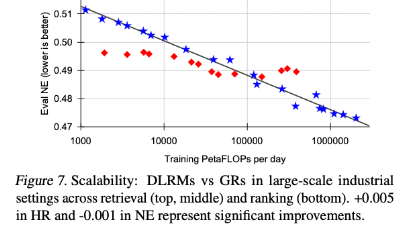
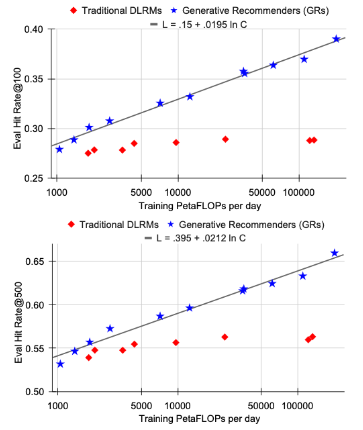
最终,我们所有主要的指标,包括检索任务中的Hit Rate@100和Hit Rate@500,以及排名任务中的NE,只要给定适当的超参数,都会根据所使用的计算量呈现出幂律缩放。
我们在三个数量级上观察到这一现象,一直到我们能够测试的最大模型(具有8192的序列长度、1024的嵌入维度和24层的HSTU),此时我们使用的总计算量(标准化为一年的使用量,因为我们采用的是标准的流式训练设置)接近于GPT-3(Brown等人,2020年)和LLaMa2(Touvron等人,2023b)所使用的总训练计算量,如图1所示。
在合理的范围内,确切的模型超参数相比于应用的总训练计算量来说,其影响较小。
与语言建模不同,在推荐系统中序列长度起着更加重要的作用,需要同时增加序列长度和其他参数。
这可能是我们提出方法的最重要优势,因为我们首次展示了大型语言模型的扩展法则也可能适用于大规模推荐系统。
4.2 性能评估
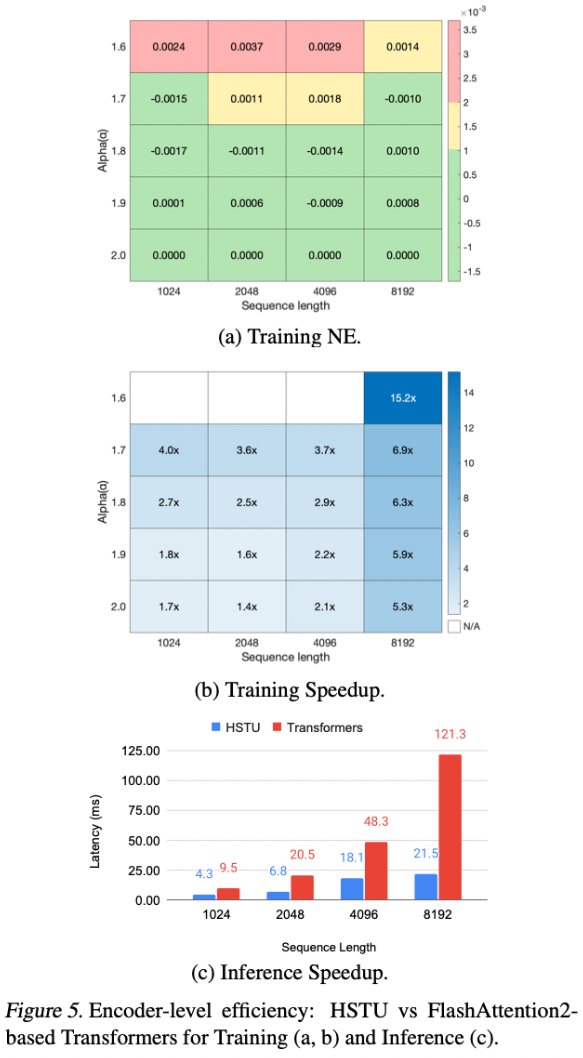
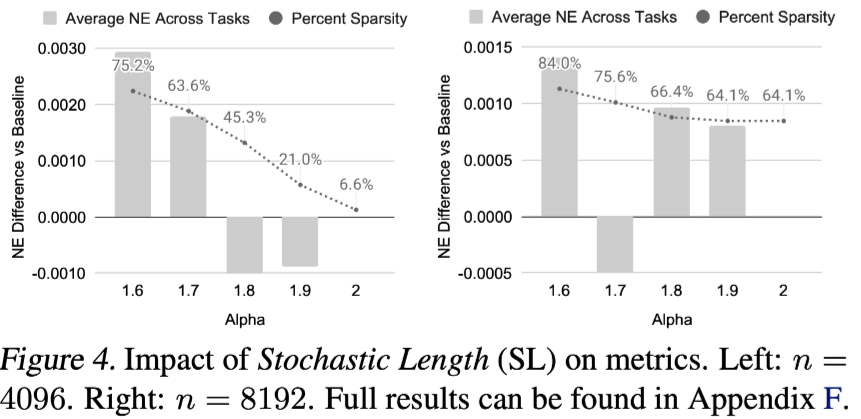
随机长度(Stochastic Length)图4和图5(a)显示了随机长度(SL)对模型评估的影响。
在α=1.6时,长度为4096的序列在大多数情况下被转换为长度为776的序列,或者去除80%以上的token。
这一证据支持,对于合适的α,SL不会对模型质量产生负面影响,并允许高稀疏性来降低训练成本。我们在附录F.3中进一步验证了SL显著优于现有的长度外推技术。
编码器效率(Encoder Efficiency)图5比较了HSTU和Transformer编码器在训练和推理设置中的效率。
对于Transformer,我们使用最先进的FlashAttention-2实现。
我们考虑从1024到8192的序列长度,并在训练期间应用随机长度(SL)。
在评估中,我们对HSTU和Transformer(d=512,h=8,
并且考虑到HSTU优于没有
如第4.1.2节。本文在工业数据集中,比较了bfloat16【torch2以上才有,1.13没有】在NVIDIA H100 GPU上的编码器级性能。总的来说,HSTU在训练和推理方面的效率分别比Transformers高出15.2倍和5.6倍。
此外,如第3.3节所述,激活内存(activation memory)使用量的减少使我们能够使用HSTU构建比Transformers更深2倍的网络。